** 기본 DB지식
- 데이터베이스Database란 일반적으로 컴퓨터 시스템에 전자 방식으로 저장된 구조화된 정보 또는 데이터의 체계적인 집합
- DBMS란(DataBase Management System) 사용자와 데이터베이스 사이에서 사용자의 요구에 따라 정보를 생성해 주고 데이터베이스를 관리해 주는 소프트웨어
- SQL이란(Strucured Query Language) 관계형 데이터베이스 관리 시스템의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어 RDBMS에서 자료의 검색과 관리, 데이터베이스 스키마 생성과 수정, 데이터베이스 객체 접근 조정 관리를 위해 고안되었음
💡 SQL에서 JOIN이란?
조인은 두 개의 테이블을 서로 묶어서 하나의 결과를 만들어 내는 것을 말한다
조인을 쓰면 두 개의 테이블을 엮어서 원하는 데이터를 추출할 수 있다
두 테이블의 조인을 위해서는 기본키(PRIMARY KEY, PK)와 외래키(FOREIGN KEY, FK)관계로 맺어져야 한다. (일대다 관계)
- INNER JOIN(내부 조인)은 두 테이블을 조인할 때, 두 테이블에 모두 지정한 열의 데이터가 있어야 한다.
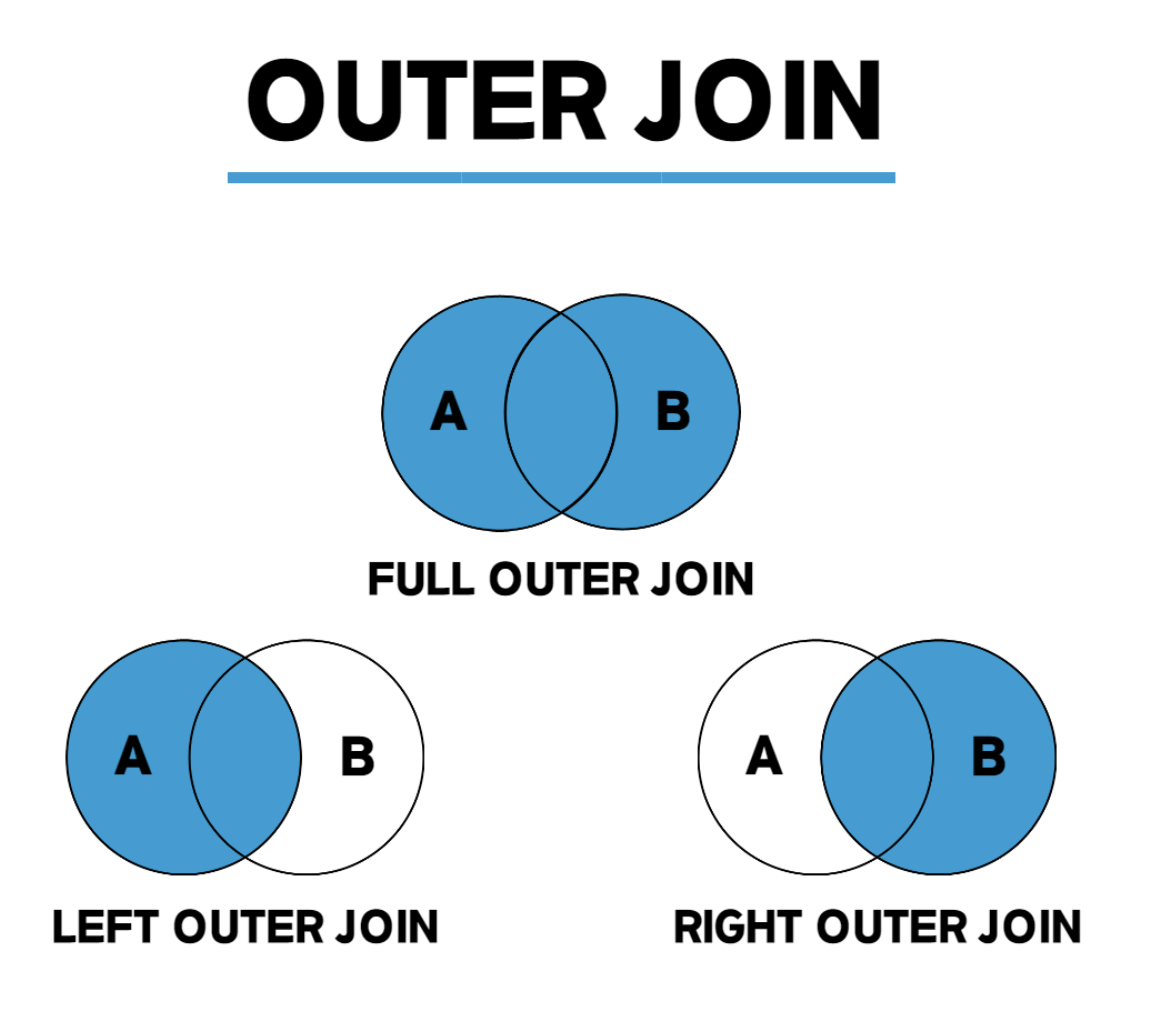
- OUTER JOIN(외부 조인)은 두 테이블을 조인할 때, 1개의 테이블에만 데이터가 있어도 결과가 나온다.
- CROSS JOIN(상호 조인)은 한쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인하는 기능이다.
- SELF JOIN(자체 조인)은 자신이 자신과 조인한다는 의미로, 1개의 테이블을 사용한다
💡 left outer join, inner join 차이를 설명해 주세요
중복 없는 열(column) A, B를 Join한다고 가정했을 때,
INNER JOIN은 A와 B의 교집합을 얻을 수 있다.
교집합의 경우 어느 테이블을 먼저 읽어도 결과가 달라지지 않으므로 MySQL 옵티마이저가 JOIN의 순서를 조절해서 다양한 방법으로 최적화를 수행할 수 있다.
OUTER JOIN은 특정 테이블을 기준으로 데이터를 보여준다. (full은 예외, A와 B의 합집합을 얻을 수 있다.)
이 경우 반드시 OUTER가 되는 테이블을 먼저 읽어야 하기 때문에 조인 순서를 옵티마이저가 선택할 수 없다.
INNER JOIN은 조인의 양쪽 테이블 모두 레코드가 존재하는 경우에만 레코드가 반환되며,
OUTER JOIN은 아우터 테이블에 존재하면 레코드 반환, 테이블에 값이 없으면 NULL로 채운다.
OUTER JOIN과 INNER JOIN은 용도가 다르므로 적절한 사용법을 익히고 요구되는 요건에 맞게 사용하는 것이 중요하다.
INNER JOIN의 경우 교집합이므로 원하는 결과가 나오지 않을 우려가 생기고, OUTER JOIN으로 실행하면 쿼리의 처리가 느려진다고 생각한다. 하지만 가져오는 쿼리의 결과 건수가 같다면 성능 차이는 거의 발생하지 않으므로 적절히 사용하는 것이 더 중요하다.
JOIN의 종류
- INNER JOIN
- OUTER JOIN : LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN
- CROSS JOIN (mysql)
- SELF JOIN (mysql)
JOIN으로 어느 테이블을 먼저 읽을지를 결정하며, 처리할 작업량을 결정한다
INNER JOIN
두 테이블의 교집합을 얻는다. 일반적으로 ‘조인’이라고 할 때 사용한다.
RIGHT OUTER JOIN
오른쪽 테이블 기준으로 JOIN한다 오른쪽 테이블 B 의 모든 데이터와 B와 A 테이블의 중복데이터들을 가져온다
일치하는 데이터가 없을 경우 null로 채워 반환하며 오른쪽 테이블(B)에 데이터가 없으면 A에 데이터가 있더라도 모두 null로 채워 가져온다.

LEFT OUTER JOIN
왼쪽에 있는 테이블을 기준으로 JOIN한다
select * from A LEFT OUTER JOIN B ON (A.번호 = B.번호)
select * from A ,B WHERE A.번호 =B.번호(+);
A에 있는 모든 행과 B에 함께 있는 행을 얻는다.
FULL OUTER JOIN
Full-Outer-Join은 A와 B의 합집합을 얻는다
만약 어떤 행의 A에는 데이터가 있고 B에는 비어있는 경우 B 부분은 null이며, 반대의 경우에는 A 부분이 null을 넣어 반환한다.
** MySQL에서는 full outer join을 지원하지 않아 inner join과 outer join을 적절히 섞어 사용해 같은 결과를 얻는다
CROSS JOIN
한쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인시키는 기능
상호 조인 결과의 전체 행 개수는 두 테이블의 각 행의 개수를 곱한 수만큼 나온다
카티션 곱(CARTESIAN PRODUCT)이라 부르기도 함
SELECT *
FROM <첫 번째 테이블>
CROSS JOIN <두 번째 테이블>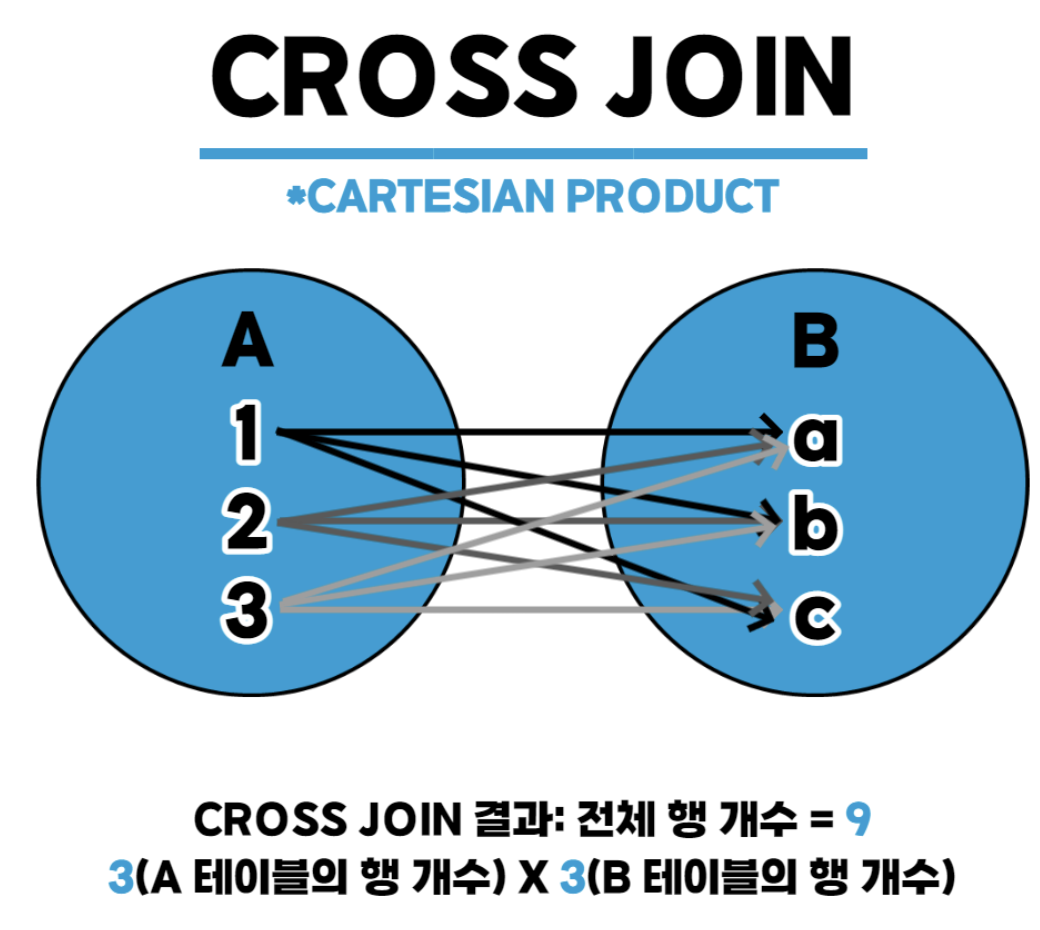
SELF JOIN
self join은 자기 자신과 join. 별도의 문법이 있는 것은 아니고 1개로 조인하면 자체 조인이며 1개의 테이블을 사용한다
참고 :
혼자 공부하는 SQL 책
https://hongong.hanbit.co.kr/sql-기본-문법-joininner-outer-cross-self-join/
https://helloworld92.tistory.com/34
https://devlog-wjdrbs96.tistory.com/347
💡 RDB - NoSQL를 비교 설명해 주세요
RDBMS : 관계형Relational 데이터베이스 관리 시스템DBMS
RDBMS는 RDB를 관리하는 시스템
RDB는 관계형 데이터 모델을 기초로 두고 모든 데이터를 2차원 테이블 형태로 표현하는 데이터베이스
어떤 테이블이 다른 테이블들과 관계를 맺고 모여있는 집합체라 볼 수 있다
RDBMS에서는 테이블간의 관계에서 외래 키(foreign key)를 이용한 테이블 간 Join이 가능하다
NoSQL : Not Only SQL
RDB 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미한다
NoSQL에서는 RDBMS와는 달리 테이블 간 관계를 정의하지 않는다
데이터 테이블은 그냥 하나의 테이블이며 테이블 간의 관계를 정의하지 않아 일반적으로 테이블 간 Join도 불가능하다
등장배경 : 빅데이터의 등장으로 데이터와 트래픽이 기하급수적으로 증가함에 따라 RDBMS에 단점인 성능저하가 나타났다. 성능을 향상시키기 위해서는 비싼 장비(Scale-Up의 특징)를 사용해야했는데 이 때문에 비용이 기하급수적으로 증가하였다. 따라서 데이터 일관성은 포기하고 비용을 고려하여, 여러 대의 데이터에 분산하여 저장하는 Scale-Out을 목표로 등장한 것이 NoSQL이다. NoSQL은 다양한 데이터 타입을 지원하여 👍 수평적 확장성(=Scale Out)이라는 큰 장점을 지닌다.
NoSQL 종류 :
- Key-Value Database
- Document Database
- Wide Column Database
- Graph Database
RDBMS
👍 장점
- 명확한 데이터 구조를 보장 (RDBMS는 정해진 스키마에 따라 데이터를 저장함)
- 각 데이터를 중복없이 한 번만 저장
👎 단점
- 테이블 간 관계를 맺고 있어 시스템이 커질 경우 JOIN문이 많은 복잡한 쿼리가 만들어질 수 있다
- 성능 향상을 위해서는 서버의 성능을 향상 시켜야하는 Scale-up만을 지원 = 확장할 수록 high cost
- 스키마로 인해 데이터가 유연하지 못하며, 이후 변경 시 번거로움
NoSQL
👍 장점
- 스키마가 없기 때문에 유연하며 자유로운 데이터 구조를 가짐(언제든 저장된 데이터를 조정하고 새로운 필드를 추가할 수 있다)
- 데이터 분산이 용이
- 성능 향상을 위한 Scale-up 뿐만이 아닌 Scale-out 또한 가능
👎 단점
- 데이터 중복이 발생, 중복된 데이터가 변경될 경우 수정을 모든 컬렉션에서 수행해야함
- 스키마가 존재하지 않기에 명확한 데이터 구조를 보장하지 않으며 데이터 구조 결정이 어려움
RDBMS, NoSQL의 사용
RDBMS는 데이터 구조가 명확하며 변경 될 여지가 없을 때 명확한 스키마가 중요한 경우 사용하며, 중복된 데이터가 없어(데이터 무결성) 변경이 용이하기 때문에 관계를 맺고 있는 데이터가 자주 변경이 이루어지는 시스템에 적합하다
NoSQL은 정확한 데이터 구조를 알 수 없고 데이터가 변경/확장이 될 수 있는 경우에 사용. 데이터 중복이 발생할 수 있으며 중복된 데이터가 변경될 시에는 모든 컬렉션에서 수정을 해야하므로 Update가 많이 이루어지지 않는 시스템, Scale-out이 가능하므로 막대한 데이터를 저장해야 해서 Database를 Scale-Out를 해야 되는 시스템에 적합
'CS > DB & SQL' 카테고리의 다른 글
| [기술면접] DB | Nested Loop, Sort-Merge, Hash Join (0) | 2023.09.07 |
|---|---|
| [기술면접] DB 문답 | index 상세 (0) | 2023.09.05 |
| [기술면접] DB 문답 | Transaction의 Lock, Index (0) | 2023.09.04 |
| [기술면접] DB 문답 | Transaction + SQL언어 (0) | 2023.09.01 |
| [기술면접] DB | 모델링 N:M관계 (0) | 2023.08.28 |