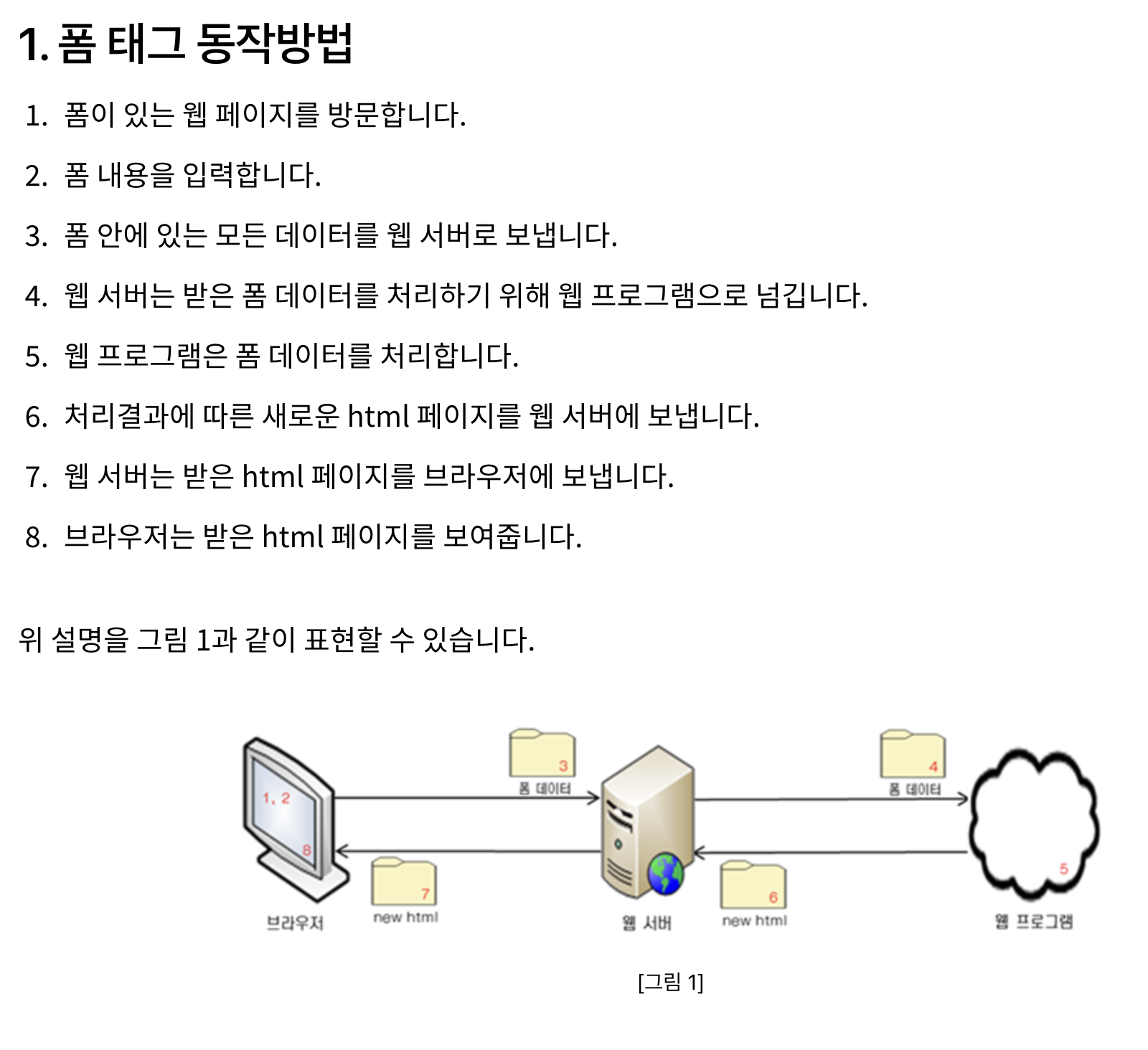
[TIL] 팀프, 페이지네이션 구현
오늘 한 것
팀원들과 어제 회의 결과 각자 부족한 부분을 채우거나
팀프에 추가 구현사항을 추가하기로 하였다.
팀프 SA 회의때 이야기 나누었던 my comment를 모아서 볼 수 있는 부분을 더 구현하고 싶어서
Paginator 를 연구하고 구현해보았다.
하라는 튜토리얼은 안하고!
새롭게 알게 된 것
- 커리큘럼에서 당장 하라는 것만 하라는 이유가 있다.
이유는 아래 서술
- Paginator
- 장고의 페이지를 만들어주는 내장기능
- 버전1 에서는 활발히 쓰였으나 View기능 이후 기능 개발을 줄인 듯하다.
- 장고 레퍼런스에도 간단히 서술되어있다.
- View : 장고 지원 툴, 개발을 빠르고 편리하게 만들어준다.
적용 과정
이전 팀원분도 그렇고 이번 팀원분께서도 pagination기능 개발에 힘쓰시는 것을 보면서 관심이 갔다.
paginator라는 기능을 알게되었고,
my comment page 를 보는데에도 데이터가 많아지면 결국 필요할 것이라는 생각이 들어
팀과제의 남은 시간동안 개인적인 구현 과제로 잡아보기로 했다.
- html 기본 지식 공부
- pagination 장고 문서 및 예제 찾아보기
- 클론 코딩으로 구현하기
...
- View기능을 알아버림(아마 선행학습)
- generic View 와 하위 함수 맛보기 공부
- 클론 코딩 및 코드 이것저것 덧붙여보기
- 과정 0 - html 기본 지식 알기
기능을 혼자 만들기 위해서는 기본적인 html 지식이 있어야한다.
기껏 만든 기능을 html에 적용하지 못하면 모든 삽질이 허사가 될테니까!
html의 form action method가 어떤 기능을 하는지,
action에 들어갈 url경로를 어떻게 설정하느냐에따라 사용자의 url이 어떻게 변화하는지를 먼저 숙지하자.
역시나 잊어버린 금붕어... 다시 공부했다.
form은 웹페이지 내에 데이터를 요청하는 폼이 있는 곳에 사용하며
get / post method와 action을 기본적으로 가진다.
get은 사용자의 눈에도 보이게(url이 바뀜), Read기능을 담당하고
post는 뒤에서 움직이며(url이 바뀌지 않음) Create Update Delete 요청을 수행한다.
(폼 안에 다양한 기능을 넣어 수행하도록 함)
action 에 url경로를 작성하는데에는 여러 방법이 있다.
- 전체 경로 작성하기 (프로젝트 내 경로 작성)
- / 를 앞에 붙여서 작성하면 /서버 경로
- / 없이 작성하면 현재 경로에 + ___.html 파일
1) <form action="../comment">
http://localhoset:8000/my/comment
2) <form action="../../comment">
http://localhoset:8000/comment
3) <form action="comment">
http://localhoset:8000/my/100/comment
4) <form action="/comment">
http://localhoset:8000/comment
<form action="이동경로">,
<a href="이동경로">
location.href="이동경로"
등의 경로 설정방법도 있으나 부트스트랩을 사용하면 form을 주로 쓰게되는 듯.
+++ 추가 +++
장고 template 기능
(‘[%s] : 지금까지 댓글 [%d]개를 작성했습니다.’ % title, (int(entry_id))
html에 이렇게 작성하면 %뒤의 글을 각각 넣어준다고한다!
- 과정 1-1 - 약간의 삽질. 수동으로 페이지 기능 만들어보기..
목표 : my comment 리스트 가져와 해당 페이지에 출력하기
Pagination
한정된 네트워크 자원을 효율적으로 사용하기 위해 데이터를 분할하여 가져오는 방법이다
스크롤, 더보기, 페이지 넘김 등의 방법이 있고
요청이 있을 때 적정량의 데이터를 재전송해주는 방식으로 동작함
- Offset-based pagination
offset쿼리를 사용해 페이지 단위로 구분하여 요청하고 응답함
row 수를 제한해서 db에 요청함
sql쿼리문을 이용한다. - Cursor-based Pagination
cursor개념을 사용해서 응답의 마지막 데이터를 기분으로 다음 n개를 요청하면 응답함
[참조] : https://docs.djangoproject.com/en/4.2/topics/pagination/
DB에 넣은 글을 가져와서 화면을 출력하려면 모델을 불러와 모듈로 적용시키고,
from .models import CommentModel
모델에서 자료를 꺼내온다.
- get 하나 가져오기
- filter (조건에 해당하는) 여러개 가져오기
- all 모두다 가져오기 (조건지정도 가능은 하다)
CommentModel.objects.all()[0:10]
#[시작위치:끝날위치]
테스트를 위해 [0:10] 범위연산자를 사용해 얼마만큼의 db테이블을 한 번에 가져올지 지정한다.
+ 이렇게 하면 데이터를 모두 가져온 다음 10개를 뽑아서 주니까 혹시 정말 10개만 필요하다면 limit를 걸어주어야한다.
한 페이지에 가져오고 싶은 만큼의 db정보의 양을 변수로 지정해서 넣으면 원하는 만큼의 글을 가져올 수 있다.
cmt_amount = 10
start_cmt = (page-1)* cmt_amount
end_cmt = start_cmt + cmt_amount
#[start_cmt:end_cmt]
이왕이면 최신 댓글부터 보도록 정리한다.
시간 순 정렬하기
* order_by('created') : created 순서대로 정렬
* order_by('-created') : created 역순으로 정렬
def index(request, page=1):
cmt_amount = 10
start_cmt = (page-1) * cmt_amount
end_cmt = start_cmt + cmt_amount
title = ‘내 댓글 목록'
my_comments = CommentModel.objects.all().order_by('-created_at')[start_cmt:end_cmt]
return (‘[%s] : 지금까지 댓글 [%d]개를 작성했습니다.’ % title, (int(entry_id))
여기까지 하고 아차 삽질이구나 함
그래도 원리를 알면 좋지..
- 과정 1-2 - 불러온 댓글 목록에 장고 paginator 적용
방법 1 pagiantor 객체를 for문으로 전달해주기
페이지네이터 import
from django.core.paginator import Paginator
Paginator(첫번째 인자, 두번째 인자)
첫번째 인자 : 불러오는 db테이블, 목록
두번째 인자 : 한페이지에 몇개의 포스트를 볼지 정하기
def _페이지네이터 적용할 함수_(request):
comment_list = CommentModel.objects.all()
page = request.GET.get('page')
pagenator = Paginator(comment_list, 10)
page_obj = paginator.page(page)
return render(request, '/comment/my', {'comment_list':comment_list, 'page_obj':page_obj})
comment_list 는 페이지 관계없이 전체 포스팅이 담겨있는 객체
page_obj 는 페이지마다 할당된 포스팅이 담긴객체이므로
담고자하는 template에 넣어준다.
{% for comment in page_obj %}
<li>{{ comment.content }}</li>
{% end for %}
여기까지 읽고 쓰면서 내가 원하는 기능이 아니구나 깨닫고 재공부에 들어갔다.
이후 내용이 필요하다면 참조를 보거나 페이지네이션에 대해 검색해보자.
[참조]:
방법 2. '더 보기' 기능처럼 만들기
'더 보기'나 스크롤로 댓글을 최신순 10개씩 한 페이지에 불러오고 싶다.
내릴때, 더보기를 누를때 db에서 정보를 가져와주도록 만들고자했다.
views.py에 추가한다.
def my_comment_view(request, template='함수를 넣을 템플릿.html'):
author = settings.AUTH_USER_MODEL.name
context = {'my_comments': CommentModel.objects.all(author=author)}
return render_to_response(template, context, context_instance=RequestContext(request))author = author ..어떤 유저가 적은 글인지 식별하기위한 식별자로 넣는다
앞의 author는 가져온 db테이블의 author
뒤의 author는 연결되어있는 user의 이름.
이렇게 직접 지정해줌으로써 외래키(ForeignKey)로 인해 ManyToOne 관계에 있는 유저내용을 가져올 수 있다.
<h2> 내 댓글 목록 </h2>
{% for my_cmt in my_comments %}
{% my_cmt %}
{% endfor %}
[참조] : https://django-endless-pagination.readthedocs.io/en/latest/twitter_pagination.html
[참조] : https://docs.djangoproject.com/ko/4.2/topics/pagination/
그리고 위의 공부들을 합해서 페이지네이터를 적용한 함수.
못쓰겠지만 아까우니까(?) 남겨두자
요 함수는 page 관련해서 좀 손을 봐야한다.
def my_comment_view(request, page=1):
if request.method == "GET":
# 내 댓글 불러오기, author정보기반
author = CommentModel.author
my_comment = CommentModel.objects.all(author=author).order_by("-created")
paginator = Paginator(my_comment, 10)
page = request.GET.get("page")
page_obj = paginator.page(page)
return render_to_response(
"/comment/my", {"my_comment": my_comment, "page_obj": page_obj}
)
이후 url을 연결하는 과정을 거치고 서버에 무언가 뜨는 것까지는 봤다.
그런데 여기까지 진행하고 페이지네이션을 더 찾아보다가 대 충격적인 사실을 알게되었다.
맨 상단에 적어둔 커리큘럼 진행에 발맞춤이 필요한 이유가 이것이다..
다음 주 부터 시작될 심화과정에서 사용하는 generic View (심지어 튜토리얼에서 접한!)를 사용하면
아주 편하게 페이징 기능을 구현할 수 있다는 것을...........
- 과정 3 - 제네릭 뷰를 사용하자!
pagenator를 하려면 제네릭 뷰를 알아야 쉽구나! 를 알게된 후의 행보
위 함수는 주석처리해두고 generic View를 공부, 클론 코딩했다.
제네릭 뷰 genericView
List보여주기, template보여주기 ,url을 redirect해주는 뷰 등
개발할때 자주 등장하는 내용을 모아둔 장고의 기본 view 도구 묶음이다
관련 내용은 이후 정리해서 til작성할것임:)
import 경로는 이러함
from django.views.generic import ListView
제네릭 뷰로 보이는 화면 만드는 순서..
1) 클래스를 만들고 상속 받기
2) model 지정해주기(어떤 테이블에서 가져오는지 명시.)
3) template_name = 템플릿 파일 지정해주기
4) contect_object_name = 객체 리스트에 대한 변수명 정해주기. 안하면 object_list로 기본 설정되는 듯
- This is provided in addition to the default object_list entry, but contains exactly the same data
5) paginate_by = 페이징을 할거라면 한 번에 가져올 객체 리스트 개수를 정해준다.
6) 가져올 상세 db테이블을 함수로 지정한다.
7) 클래스 인스턴스 변수를 만든다
8) url에 연결한다. views.클래스인스턴스변수.as_view()를 붙여준다
9) html 내용 손보면 끝!
class MyCommentList(generic.ListView):
# ListView를 사용해 댓글 10개씩 보여주기
model = CommentModel
template_name = "comments/my_comment.html"
context_object_name = "latest_comment_list" #이름 잘 기억
paginate_by = 10
이렇게... 간단해진다.
그리고 가져올 자료는 queryset 함수로 지정한다.
def get_queryset(self):
# 최근 댓글 불러오기
my_comment = CommentModel.objects.all().order_by("-created_at")
return my_comment #이 목록을 위의 오브젝트네임으로 받아서 html에서 for문으로 굴린다
url을 적용하기 위해 클래스 인스턴스를 만들어준다.
get_my_comments = MyCommentList
url path 입력해주기
#urls.py
path("comment/my", views.get_my_comments.as_view(), name="my_comments"),
my_comments.html 내용 만들어주기
{% extends 'base.html' %}
{% block content %}
<h3>내 댓글 보기</h3>
<div class="row">
<div class="col-md-12">
<div class="media">
<div class="media-body">
<ul>
{% for comment in latest_comment_list %}
<li>
{{ comment.post.name }} | {{ comment.content }} | {{ comment.created_at }}
</li>
{% endfor %}
</ul>
</div>
</div>
</div>
</div>
{% endblock content %}
for문으로 굴리는 와중에 어떤 부분에 어떤 자료가 들어갈지 넣어준다.
user명이나 post이름을 가져오기 위해 끙끙 삽질을 좀 했는데
ForeignKey 관계에서는 다대 1이므로
1을 comment.post로 어디서든 참조할 수 있다고 한다
{{ comment.post.name }} | {{ comment.content }} | {{ comment.created_at }}
차례대로 포스트 제목 | 코멘트 내용 | 코멘트 적은 시간 (수정기능은 구현안해서 created_at으로 했다.)
느낀점:
하나 해보겠다고 수요일..오후? 부터 거하게 삽질했다
덕분에 한 기능의 발전 과정을 체험해버렸다ㅋㅋ
과정1은 버전1을 참고로한 자료였..고 과정2는 비교적 최신.이었지만 더 최신이 있었다.
구글링의 중요성을 또 한 번 알게되었다
이틀간의 삽질을 단 3시간으로 줄여주는 장고의 마법....
아 물론 삽질만 있었던 것은 아니었다.
다양한 예제를 접하면서 머릿속이 풍부해진 느낌이 든다^.^
선행학습 어렵다!
그런데 재밌다!
아무것도 모를땐 에러메시지에 화만 났는데
어느정도 로직이 파악되고 나니 오류 고치는 과정에도 즐거움이 느껴지는 것 같다.
마무리하고 푹 쉬어서 그런걸지도ㅋㅋ
주말동안은 아직 한 번도 안해본(...) 수정기능을 마저 구현해보고,
강의남은 것도 듣고.. 튜토리얼도 끝내야겠다..
시간이 남으면 테스트 하는 방법도 연구해봐야지!
=주말 없음